N-Body Simulations
Simulations of star clusters and galaxies in stellar dynamics have traditionally been called N-body simulations for no particularly good reason. The gravitational two-body and three-body problems have been at the center of the development of mathematical physics, right when Newton developed his universal theory of gravity.  The logical generalization would be to talk about the gravitational many-body problem when addressing the study of star clusters. Unfortunately, the term many-body simulations is unlikely to become popular, given that the name N-body simulations has by now been entrenched. So we'll stick with the latter term, while making a modest push for the former term by calling our master website manybody.org (the historical reason behind the term N-body rather than, say k-body or p-body for that matter, were probably connected with the original Fortran conventions that letters such as n automatically stood for integers, and that all letter were capitalized). The project on which I am spending most of my time these days is the Art of Computational Science.
The logical generalization would be to talk about the gravitational many-body problem when addressing the study of star clusters. Unfortunately, the term many-body simulations is unlikely to become popular, given that the name N-body simulations has by now been entrenched. So we'll stick with the latter term, while making a modest push for the former term by calling our master website manybody.org (the historical reason behind the term N-body rather than, say k-body or p-body for that matter, were probably connected with the original Fortran conventions that letters such as n automatically stood for integers, and that all letter were capitalized). The project on which I am spending most of my time these days is the Art of Computational Science.
Efficiency Analysis
 |
After an early type of Cambrian explosion of different methods and computer codes in the sixties, Sverre Aarseth set the tone for collaboration and friendly competition in stellar dynamics by making his codes freely available. For this, we all owe him a debt of gratitude. Throughout the seventies and eighties the Aarseth codes were the basically the only game in town, as far as simulations of dense stellar systems was concerned (collisionless simulations were generally carried with tree codes or grid-based codes).
Although Aarseth's codes had been well honed over time, and were clearly pretty efficient based on empirical criteria, no theoretical study had been done to determine the optimum choice of parameters for the central integration engine. We conducted the first such analysis in Performance Analysis of Direct N-Body Calculations, by Makino, J. & Hut, P., 1988, Astrophys. J. Suppl., 68, 833-856. There we showed that Aarseth's choice had been close to optimal, with only modest improvement still possible in the parameter choices for the Ahmed-Cohen two-timescale method.
Our study was only aimed at systems with single stars. When it became clear from observations that many star clusters contain a large fraction of their stars in primordial binaries, we repeated our analysis for the case that a significant number of binaries are present from the beginning. Our results were published as Bottlenecks in Simulations of Dense Stellar Systems, by Makino, J. & Hut, P., 1990, Astrophys. J. 365, 208-218.
Having proven the efficiency of contemporary N-body codes for scalar machines, we started to test those codes on a variety of vector supercomputers and parallel machines.
 |
We spend some time at Thinking Machines, the company that produced the then state-of-the-art Connection Machine. Our detailed study showed just how problematic it was to parallellize stellar dynamics codes in any efficient way, be they tree codes for collisionless stellar dynamics or Aarseth-type codes for collisional stellar dynamics. we published our results in a lenghty document Gravitational N-body Algorithms A Comparison between Supercomputers and a High Parallel Computer, by Makino, J. & Hut, P., 1989, Comp. Phys. Rep. 9, 199-246. A summary of some of our results appeared in Galaxies in the Connection Machine, by Makino, J. & Hut, P., 1989, in Applications of Computer Technology to Dynamical Astronomy, I.A.U. Colloq. 109, Celest. Mech. 45, 141-147.
Given the great problems we encountered in modeling star cluster evolution in efficient ways on existing computers, we made a definitive study of what it would take to simulate a small globular cluster, containing 100,000 stars. Our result were published in Modelling Globular Cluster Evolution, by Hut, P., Makino, J. & McMillan, S., 1988, Nature, 336, 31-35. We concluded that it would take a computer with an effective speed of 1 Teraflops, a speed orders of magnitude above what was available then. And given the low efficiency of general-purpose parallel computers, we would probably have to wait for a computer running at 10 Teraflops or more in order to get the effective speed we needed. It was at this point that we decided to start the GRAPE project, one year later.
Software Environment: Starlab and the Kira code
Another result of our efficient analysis was our decision to write a new N-body code from scratch. Much as we admired the various codes that Sverre Aarseth had written, we felt that after twenty years it was time to explore a different approach, if nothing else to provide more variety and thus to enable comparisons in efficiency and accuracy.
We also had a few more specific goals in mind. First, we saw the need for a fully recursive implementation of regularization techniques. Although the Aarseth codes automentically provided local coordinate patches for strongly interacting subsystems such as stellar multiples, we foresaw the need to implement even smaller and more localized patches within such patches. And rather than handcoding for all possible subdivisions, we decided to use a new data structure in the form of a flat top level tree with a hierarchical binary tree for each interacting group of particles. Second, we prefered a fully object-oriented approach, in order to make the code more modular and easier to maintain and modify. This led us to write it using the C++ language. And third, we tried to minimize the tasks relegated to the central integrator code, while keeping as much as possible other tasks related to set-up and analysis reserved for separate programs.
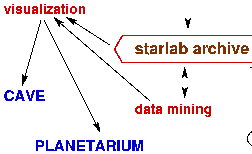 The result was the Kira code, as we called the integrator, and the development of an embedding environment, Starlab. We started the development of Starlab in 1992, after rewriting an earlier version, written in C, that I had developed during my sabbatical at Tokyo University in 1989. Starlab was inspired by Nemo, an earlier environment for simulations in stellar dynamics, but optimized for collisionless stellar dynamics, i.e. for simulating the dynamics of galaxies and clusters of galaxies, rather than star cluster. The first versions of Nemo were developed during 1986-1988, and described briefly in An Environment for Experiments in Stellar Dynamics, by Barnes, J., Hernquist, L. E., Hut, P. & Teuben, P. 1998, Bulletin of the American Astronomical Society, Vol. 20, p.706.
The result was the Kira code, as we called the integrator, and the development of an embedding environment, Starlab. We started the development of Starlab in 1992, after rewriting an earlier version, written in C, that I had developed during my sabbatical at Tokyo University in 1989. Starlab was inspired by Nemo, an earlier environment for simulations in stellar dynamics, but optimized for collisionless stellar dynamics, i.e. for simulating the dynamics of galaxies and clusters of galaxies, rather than star cluster. The first versions of Nemo were developed during 1986-1988, and described briefly in An Environment for Experiments in Stellar Dynamics, by Barnes, J., Hernquist, L. E., Hut, P. & Teuben, P. 1998, Bulletin of the American Astronomical Society, Vol. 20, p.706.
For a review of the Starlab environment, and its connections to archiving, visualization, and virtual observatories, see: The Starlab Environment for Dense Stellar Systems, by Hut, P., 2002, in Astrophysical Supercomputing Using Particle Simulations, IAU Symposium 208, ed.: P. Hut and J. Makino.
Visualization
The great speed of the GRAPE computers gave us the ability to handle ever larger number of particles. Howeve,r this also brought a need for more sophisticated forms of visualization. Specifically, we must easily and interactively zoom in on regions where interesting `reactions' occur, typically on scales in space and time that are many orders of magnitude smaller than the overall billions of years and hundreds of light years of a typical star cluster history. A central component of this enormous data mining challenge calls for the development of ways to navigate freely and interactively throughout the full 4-dimensional history of the space-time evolution of a realistic million-star system.
 |
We have begun to take concrete steps in this direction. At the recent conference on Stellar Collisions and Mergers at the American Museum of Natural History, in 2000, we were able to couple existing visualization software with simulations of clusters containing ten thousand stars, for periods of a few million years. Using the all-digital projection system in the newly rebuilt Hayden planetarium, we immersed an audience of astrophysicists in the environment of a dense evolving star cluster. Since then we have developed various tools to allow us to handle larger data sets in more flexible ways (see an article in space.com about our work). Our goal is to be able to `fly through' a star cluster interactively, and thereby to allowed flexible inspection of interesting subsystems, such as strongly interacting multiple star systems.
Some preliminary results have been published in two papers, Immersive 4D Interactive Visualization of Large-Scale Simulations, by Teuben, P.J., Hut, P., Levy, S., Makino, J., McMillan, S., Portegies Zwart, S., Shara, M., & Emmart, C.; 2001, in Astronomical Data Analysis Software and Systems X, ASP Conference Series, Vol. 238 (San Francisco: ASP) eds. Harnden, Jr. F.R., Primini, F.A., & Payne, H.E. (San Francisco: ASP), 499-502 (available in preprint form as astro-ph/0101334); and Theory in a Virtual Observatory, by Teuben, P., DeYoung, D., Hut, P., Levy, S., Makino, J., McMillan, S., Portegies Zwart, S., Slavin, S, 2002, in ASP Conf. Ser., Vol. xxx, Astronomical Data Analysis Software and Systems XI (available in preprint form as astro-ph/0111478). Some of the main issues have also been addressed in a Panel Discussion on Observing Simulations and Simulating Observations, by Hut, P., Cool, A., Bailyn, C., McMillan, S., Livio, M. & Shara, M.; 2002, in Stellar Collisions, Mergers, and their Consequences, ASP Conference Series, ed.: M. Shara (available in preprint form as astro-ph/0105197).
Validation
 |
Increasingly, the main problem in any type of large-scale simulation is validation. How do we know that a complex simulation gives reliable results? For relatively simple systems, we can compare numerical solutions with analytical predictions, but as soon as a situation becomes too complex, analytical tools no longer can provide much guidance. For pure stellar dynamics simulations, Douglas Heggie organized what he called a collaborative experiment, also known as Kyoto I, since the first public discussion of the results took place during the 1997 general assembly of the IAU in Kyoto. It was a nice touch to stress the collaboration, rather than competition aspects in this comparative validation exercise. The outcome of the meta experiment of comparing experiments was surprising: the differences between the various simulation approaches were in several ways larger than expected, and the analysis of the discrepancies led to fascinating questions and new ways of understanding aspects of N-body simulations.
After the pure stellar dynamics comparisons, Douglas took on a far more daunting task, that of comparing simulations that included stellar evolution effects. The potential diversity of approaches, and the number of free parameters, becomes far larger than it already was for the gravity-only case. The first effort at such a comparison was launched again in Japan, in 2001, but this time in Tokyo, during IAU symposium 208 which Jun Makino and I organized there in the summer. In order to stress the connection with the previous collaborative experiment, Douglas decided to call this extended experiment Kyoto II. It is still underway, and the results are likely to be discussed in more detail by 2003 (note that Douglas has listed the year 2012 as his estimate target for the publication of the definite paper for this experiment ....).
The Art of Computational Science
 |
Jun Makino and I have started a new open source project in 2003, where we want to integrate research and education. We plan to write a ten-volume book series, The Art of Computational Science, in which we provide a student with a hands-on guide to building a computational laboratory, and doing state-of-the-art research with it. The series will be self-contained: a high-school student should be able to start at page 1, and work her way through the series.
While there are many books on programming and on algorithms, there are hardly any books on the art and science of setting up a complete software environment for scientific simulations. Using stellar dynamics as an example, we construct such an environment from scratch, while providing the software and documentation with it. Our hope is that others will add to our effort, by extending our example to other areas of (astro)physics as well as other scientific disciplines.
See also:
- Science and Scientific Software Development, by Hut, P. 2004, invited contribution to The World Question Center, on the edge web site;
- Computational Astrophysics (in Japanese), by Hut, P. & Kokubo, E.; 2003, The Astronomical Herald 96, Number 12, pp. 636-637.
- Dense Stellar Systems as Laboratories for Fundamental Physics, by Hut, P.; 2006, in A Life With Stars eds. L. Kaper, M. van der Klis and R. Wijers [Amsterdam: Elsevier] (available in preprint form as astro-ph/0601232).
- Virtual Laboratories, by Hut, P.; 2007, Prog. Theor. Phys. 164, 38-53. (available in preprint form as astro-ph/0610222).
- Modeling Dense Stellar Systems, by Hut, P., Mineshige, S., Heggie, D.C. & Makino, J. 2007, Prog. Theor. Phys. Suppl. 118, 187-209. (available in preprint form as arXiv.org/0707.4293).
- Virtual Laboratories and Virtual Worlds, by Hut, P. 2008, in Dynamical Evolution of Dense Stellar Systems, IAU Symposium 246, eds. E. Vesperini, M. Giersz and A. Sills [Cambridge University Press]. (available in preprint form as arXiv.org/0712.1655).