The Geometry of Random Spaces
I sometimes like to think about what it might be like inside a black hole. What does that even mean? Is it really “like” anything inside a black hole? Nature keeps us from ever knowing. (Well, what we know for sure is that nature keeps us from knowing and coming back to tell anyone about it.) But mathematics and physics make some predictions.
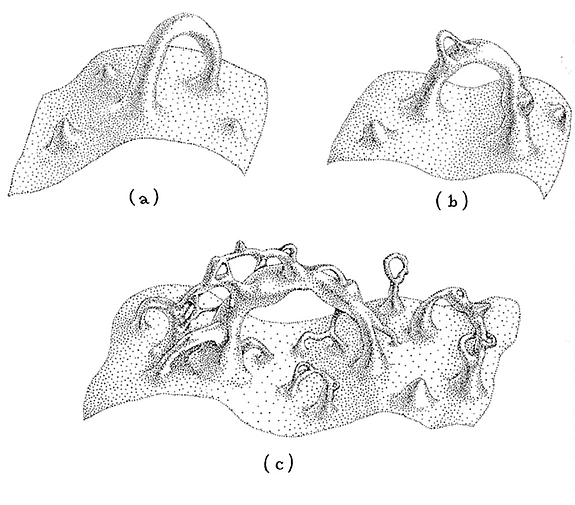
John Wheeler suggested in the 1960s that inside a black hole the fabric of spacetime might be reduced to a kind of quantum foam. Kip Thorne described the idea in his book Black Holes & Time Warps as follows (see Figure 1).
“This random, probabilistic froth is the thing of which the singularity is made, and the froth is governed by the laws of quantum gravity. In the froth, space does not have any definite shape (that is, any definite curvature, or even any definite topology). Instead, space has various probabilities for this, that, or another curvature and topology. For example, inside the singularity there might be a 0.1 percent probability for the curvature and topology of space to have the form shown in (a), and a 0.4 percent probability for the form in (b), and a 0.02 percent probability for the form in (c), and so on.”
In other words, perhaps we cannot say exactly what the properties of spacetime are in the immediate vicinity of a singularity, but perhaps we could characterize their distribution. By way of analogy, if we know that we are going to flip a fair coin a thousand times, we have no idea whether any particular flip will turn up heads or tails. But we can say that on average, we should expect about five hundred heads. Moreover, if we did the experiment many times we should expect a bell-curve shape (i.e., a normal distribution), so it is very unlikely, for example, that we would see more than six hundred heads.
To get a feel for a random space, here is an example that you can make at home. All you need is a deck of playing cards, some paper, scissors, and tape.
 |
| Figure 2 |
Make a mini-deck of twelve playing cards: ace, two, three, four, five, six, seven, eight, nine, ten, jack, queen. Cut four paper triangles. Label their sides A–Q (to correspond to your deck of cards) as in the figures above. Shuffle the cards, then take the top two cards from the deck. Say the cards are five and seven: tape the side labeled five to the side labeled seven, keeping the printed side of each triangle side up. (This ensures that you end up with an orientable surface.) Again, take the top two cards from the deck, tape the corresponding triangle sides, and repeat until you have used all twelve cards and all twelve sides are taped. As you get toward the end, you might have to really bend up your paper. But after gluing six pairs, you are mathematically certain to have a surface. What is uncertain is which surface.
One might end up with a surface homeomorphic (i.e., continuously deformable) to a sphere or a torus. But one might also end up with two spheres or a sphere and a torus, so the surface need not be connected. However, if one did this with many triangles, it would be very likely that the surface would be connected and the main question would be its genus––i.e., how many “handles” or “holes” does it have. It turns out that if one glues together n triangles randomly in this way, one should expect a surface of genus roughly n/4, on average. (This is a theorem of Nicholas Pippenger and Kristin Schleich, and independently of Nathan Dunfield and William Thurston.)
It turns out that this relatively simple model of a random space already encodes a lot of physics as n tends to infinity, and in fact one of the motivations to study it is that it serves as a two-dimensional discrete analogue of quantum gravity. So random spaces provide a mathematical model of something of fundamental interest in theoretical physics and cosmology.
Random spaces also provide interesting models within mathematics itself, as well as useful constructions in theoretical computer science. To mathematicians and theoretical computer scientists, one of the important discoveries of the last fifty years is that random objects often have desirable, hard to come by otherwise, properties. There are many examples of this paradigm by now, but one of the first was in Ramsey theory.
A combinatorial fact: among any party of six people, there must be either three mutual acquaintances or three mutual nonacquaintances. This isn’t necessarily true for five people. Let R(n) denote the smallest number of people that guarantees that if you have a party of R(n) people there are either n mutual acquaintances or n mutual non-acquaintances. So, taking the example above, R(3)=6. It is also known that R(4)=18, i.e., among any eighteen people, there must be either four mutual acquaintances or four mutual non-acquaintances. But R(n) isn’t known for any larger n.
Paul Erdős suggested that if advanced aliens threaten the Earth, telling us they will blow us up unless we tell them R(5) within a year, we should put together all the best minds and use all our computer resources and see if we can figure it out. But if they ask for R(6), he warned, we should probably attack first.
When mathematicians can’t compute something exactly, we often look for bounds or estimates. In the case of Ramsey theory, lower bounds come from somehow arranging a party with not too many mutual acquaintances or nonacquaintances. As the number of people gets large, to describe this kind of structure explicitly gets unwieldy, and after decades of people thinking about it, no one really knows how to do it very well. The best lower bounds we know come from the simple strategy of assigning acquaintanceship randomly.
This is a surprising idea at first, but it turns out to be powerful in a variety of settings. In many problems one wants to maximize some quantity under certain constraints. If the constraints seem to force extremal examples to be spread around evenly, then choosing a random example often gives a good answer. This idea is the heart of the probabilistic method.
Ramsey theory is one of many examples where the probabilistic method has been applied to combinatorics. This method has also been applied in many other areas of mathematics, including metric geometry. For example, Jean Bourgain (Professor in the School of Mathematics) showed that every finite metric space could be embedded in Euclidean space with relatively low distortion—his method was to carefully choose a random embedding and show that it has low distortion with high probability.
The probabilistic method has many applications in theoretical computer science as well. For example, a network made by randomly joining pairs of computers will be fairly robust, in the sense that everything might still be connected even if a few cables fail. Such networks are called expanders, and expanders are a very active area of research. Although random methods construct expanders easily, until recently the only explicit examples came from deep number-theoretic considerations. Peter Sarnak and Avi Wigderson (Professors in the School) have made fundamental contributions to the theory of expanders.
There has been recent interest in finding higher-dimensional analogues of expanders, and it has now been shown that certain random spaces, similar to those described above, have expander-like properties. It seems likely that these new higher-dimensional expanders will find applications in spectral clustering and topological data analysis, in sparsification of cell complexes, and probably in as yet unforeseen ways as well.